Python – pandasでCSV, TSV, Excelファイル読み込み
ここではpandasを用いたデータの入出力に話を絞りますが、さまざまなファイル形式でのデータの読み込みや書き出しを助けてくれるツールは、他のライブラリにもたくさんあります。
入出力は一般に、いくつかの大きなカテゴリに分類されます。
テキストファイルやもっと効率の良い形式のファイルをディスクから読み込むパターン、データベースからのデータを読み込むパターン、Web APIなど、ネットワーク上のソースのデータを読み込むパターンなどです。
テキスト形式のデータの読み書き
pandasの特徴は、テーブル形式のデータをデータフレーム(DataFrame)オブジェクトとして読み込む 関数がたくさんあることです。おそらく最もよく使うのはread_csvやread_tableでしょう。
| 関数 | 説明 |
| read_csv | ファイルやURL、その他のファイル系のオブジェクトから、区切り文字で区切られたデータを読み込む。デフォルトの区切り文字はコンマ。 |
| read_table | ファイルやURL、その他のファイル系のオブジェクトから、区切り文字で区切られたデータを読み込む。デフォルトの区切り文字はタブ(’\t’)。 |
| read_excel | ExcelのXLSやXLSXファイルからテーブル形式のデータを読み込む。 |
0. Iris Dataframeをsklearnから取得
まず、事前準備としてsklearn.datasetsからirisデータを取得します。CSVファイルを作成します。
from sklearn.datasets import load_iris
df_iris = pd.DataFrame(iris.data, columns = iris.feature_names)
df_iris.head()
1. DataframeをCSVファイル出力
では、取得したirisのDataframeをCSVファイルで出力します。
# Output CSV file from df
df_iris.to_csv('iris_out.csv', encoding='utf8', index=False)2. DataframeをTSVファイル出力
後続の作業で使用するため、今回はTSVファイルでも出力します。
# Output TSV file from df
df_iris.to_csv('iris_out.tsv', encoding='utf8', index=False, sep='\t')3. pandasでCSVファイル読み込み
それでは、CSVファイル(カンマ区切り)を読み込みます。
pandasのread_csvで読み込みData frame(データフレーム)を戻り値として取得できます。また、読み込んだ後に結果をDataframeの先頭5件を確認してみます。
# Read CSV file
df = pd.read_csv('iris_out.csv')
df.head()
4. pandasでTSVファイル読み込み
TSVファイル(タブ区切り)を読み込んでみます。
TSVファイルの読み込みもCSVファイルと同様に、pandasのread_csvが利用可能です。read_csvで読み込むと、戻り値としてData frameが取得できます。
# Read TSV file
df_tsv = pd.read_csv('iris_out.tsv', delimiter='\t')read_tableを使って読むことも可能です。その場合は区切り文字の指定が必要です。
df_1 = pd.read_table('iris_out.csv', sep=',')
df_1.head()
以下はpandas.read_csvとpandas.read_tableを使用する際によく与えるオプションをいくつか載せています。
| 引数 | 説明 |
| path | ファイルシステム上の位置やURL、その他のファイル系のオブジェクトを示す文字列。 |
| sepまたはdelimiter | 各行をフィールドに分割するのに用いる文字列あるいは正規表現。 |
| header | 列名として使う行の番号。デフォルトでは0(最初の行)。ヘッダ行がない場合はNoneを指定。 |
| index_col | 戻り値として得られるオブジェクトにおいて、行のインデックスとして使われる列の番号か名前。単一の名前・番号か、階層型インデックスの場合は名前・番号のリスト。 |
| names | 戻り値として得られるオブジェクトの列名のリスト。header=Noneとともに使用する |
| skiprows | ファイルの先頭で無視する行数か、読み飛ばす行番号(最初の行は0)。 |
| na_values | 欠損値で置き換える一連の値。 |
| comment | この引数に指定した文字または文字列以降を各行からコメントとして切り離す。 |
| parse_dates | データを日時として読み込もうとする。デフォルトではFalseで、Trueの場合はすべての列で読み込もうとする。すべての列に適用したくない場合は、読み込む列の番号か名前を指定する。リストの要素がタプルやリストの場合、それらの複数の列を結合して日付として読み込む(例えば、日付と時刻が2つの列に分かれている場合に使用) |
| date_parser | 日付を読み込むのに用いる関数。 |
| nrows | ファイル先頭で読み込む行数。 |
| iterator | ファイルを部分的に読み込むためのTextFileReaderオブジェクトを戻り値とする。 |
| encoding | Unicodeとして用いる文字コード(例えば、UTF-8でエンコードされたテキストの場合は’utf-8’を指定)。 |
| squeeze | 読み込まれたデータに1つの列しか含まれていない場合、シリーズ(Series)を戻り値とする。 |
| thousands | 3桁区切りのセパレータ(例えば’,’や’.’)。 |
テキスト形式でのデータの書き出し
データは、区切り文字で区切られた形式でのエクスポートもできます。先ほど読み取ったCSVファイルの1つを例に取って考えてみましょう。
df = pd.read_csv('iris_out.csv')
df.head()
データフレームのto_csvメソッドを用いると、データをカンマ区切りのファイルに書き出せます。
df.to_csv('out.csv')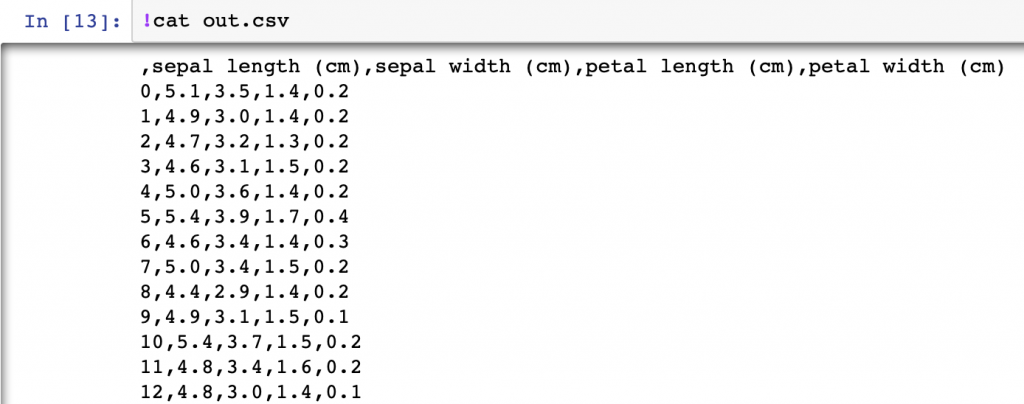
Microsoft Excelファイルの読み込み
pandasでは、Excel 2003(以降)のファイルに保存されたテーブルデータの読み込みもサポートしています。
読み込みは、ExcelFileクラスかpandas.read_excel関数のいずれか一方を用いて行います。これらのツールは、Excelファイルの読み込みにはxlrd、書き込みにはxlwt(XLSファイル用)やopenpyxl(XLSXファイル用)というアドオンパッケージを内部で使用しているので、使う場合はpipやcondaを使ってこれらのアドオンパッケージを別途インストールする必要があります。
ExcelFileを使うには、次のようにxlsファイルやxlsxファイルのパスを引数として渡して、インスタンスを作ります。
xlsx = pd.ExcelFile('ex1.xlsx')今回は、シート名を第2引数に”Sheet1″と指定すると、シート内のデータがread_excel関数によってデータフレームとして読み込めます。
# 先頭行をindexとする場合
df_xlsx = pd.read_excel(xlsx, 'Sheet1', index_col=0)
# indexを使用しない場合
df_xlsx = pd.read_excel(xlsx, 'Sheet1')
# file pathを直接指定でも読み込めます
df_xlsx = pd.read_excel('ex1.xlsx', 'Sheet1', index_col=0)
df_xlsx.head()
pandasのデータをExcel形式で書き出すには、まずExcelWriterを作成した上で、pandasオブジェクトのto_excelメソッドを用いてデータを書き込みます。
writer = pd.ExcelWriter('ex2.xlsx')
df_xlsx.to_excel(writer, 'Sheet1')
writer.save()ExcelWriterを使わずに、to_excelにファイルのパスを与えても書き出せます。
df_xlsx.to_excel('ex2.xlsx')まとめ
今回は、Python – pandasでCSV, TSV, Excelファイル読み込みについてでした。データ分析のプロセスにおいて、データの読み込みが最初のステップとなることが多いと思います。今回記載の内容の他にも細かいパラメータの設定が必要となる場合もあるかと思いますが、基本はこのような感じではないかと思います。
pandasでcsv, tsv, xlsxをdataframeに読み込んだ後のfiltering, aggregationなどのステップについては、こちらの記事もご参考ください。
dataframe同士のjoinなどについてはこちらもご参考ください。